machine learning

Is there actually anything deserving of the term AI?

There’s no telling whether machine-learned common sense is five years away, or 50.

Understanding “why” may be the key to unlocking an AI’s imagination.

A brief passage from a recent UN report describes what could be the first-known case of an autonomous weapon, powered by artificial intelligence, killing in the battlefield.

A new method could make holograms for virtual reality, 3D printing, and more. You can even run it can run on a smartphone.

New machine-learning algorithms from Columbia University detect cognitive impairment in older drivers.

Measuring a person’s movements and poses, smart clothes could be used for athletic training, rehabilitation, or health-monitoring.
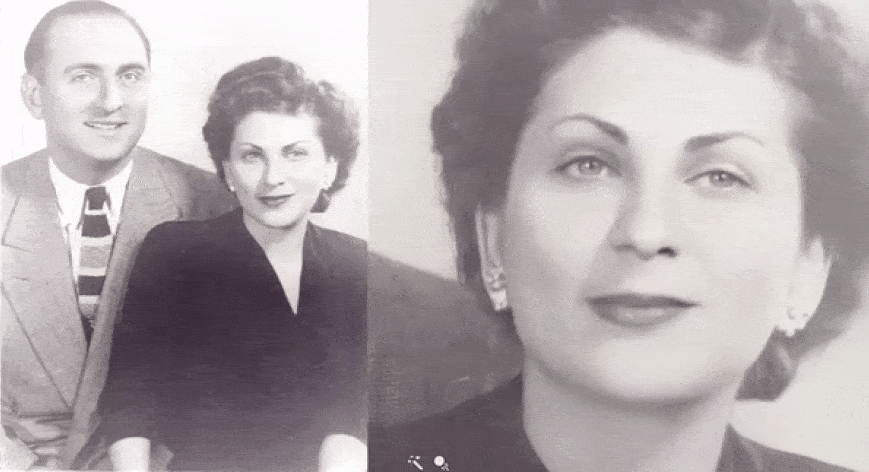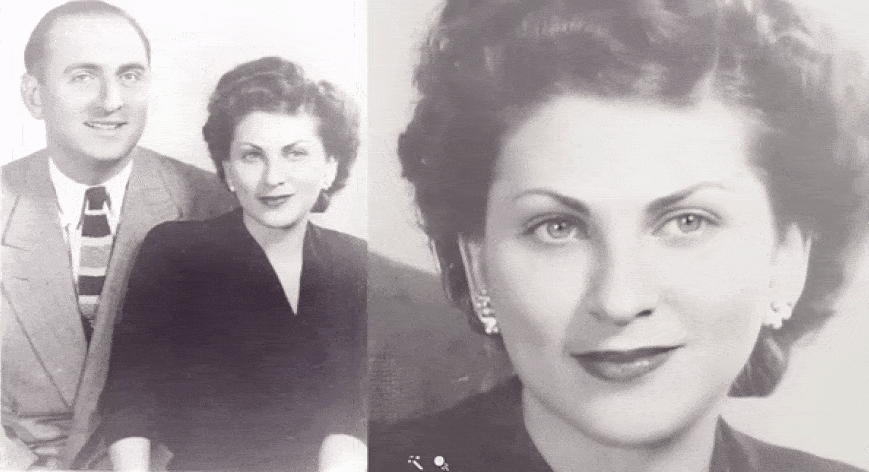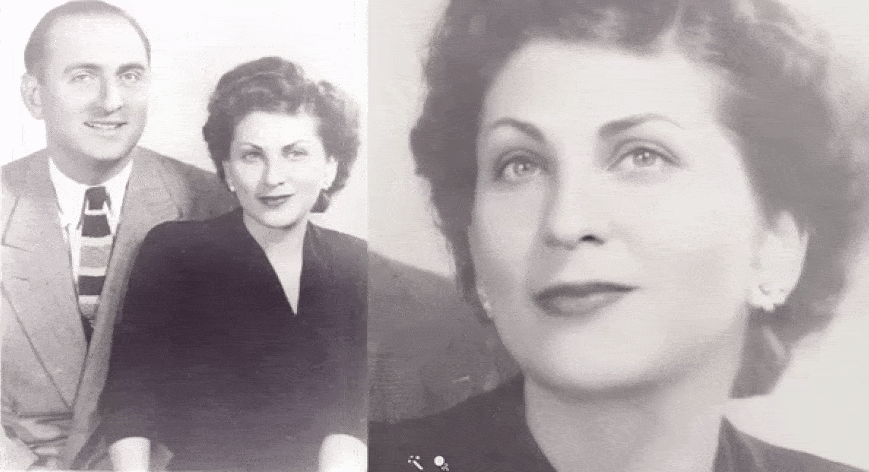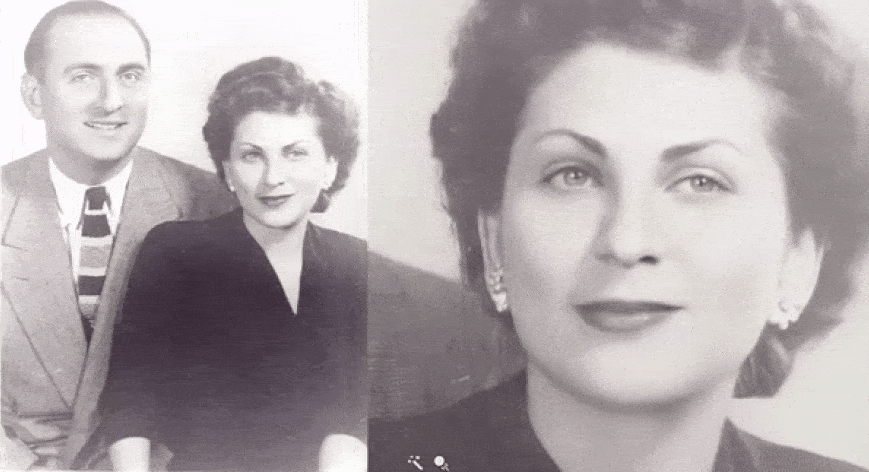
Using machine-learning technology, the genealogy company My Heritage enables users to animate static images of their relatives.

Light-emitting tattoos could indicate dehydration in athletes or health conditions in hospital patients.
A physicist creates an AI algorithm that predicts natural events and may prove the simulation hypothesis.

In the future, you might voluntarily share your social media data with your psychiatrist to inform a more accurate diagnosis.

The AI constitution can mean the difference between war and peace—or total extinction.
▸
5 min
—
with

Other cultures can differ greatly from your own, but there are commonalties in the way we express emotions.

Researchers make the case for “deep evidential regression.”

A new theory suggests that dreams’ illogical logic has an important purpose.

Textual analysis of social media posts finds users’ anxiety and suicide-risk levels are rising, among other negative trends.

A study finds 1.8 billion trees and shrubs in the Sahara desert.

Can we stop a rogue AI by teaching it ethics? That might be easier said than done.

Machine learning is a powerful and imperfect tool that should not go unmonitored.

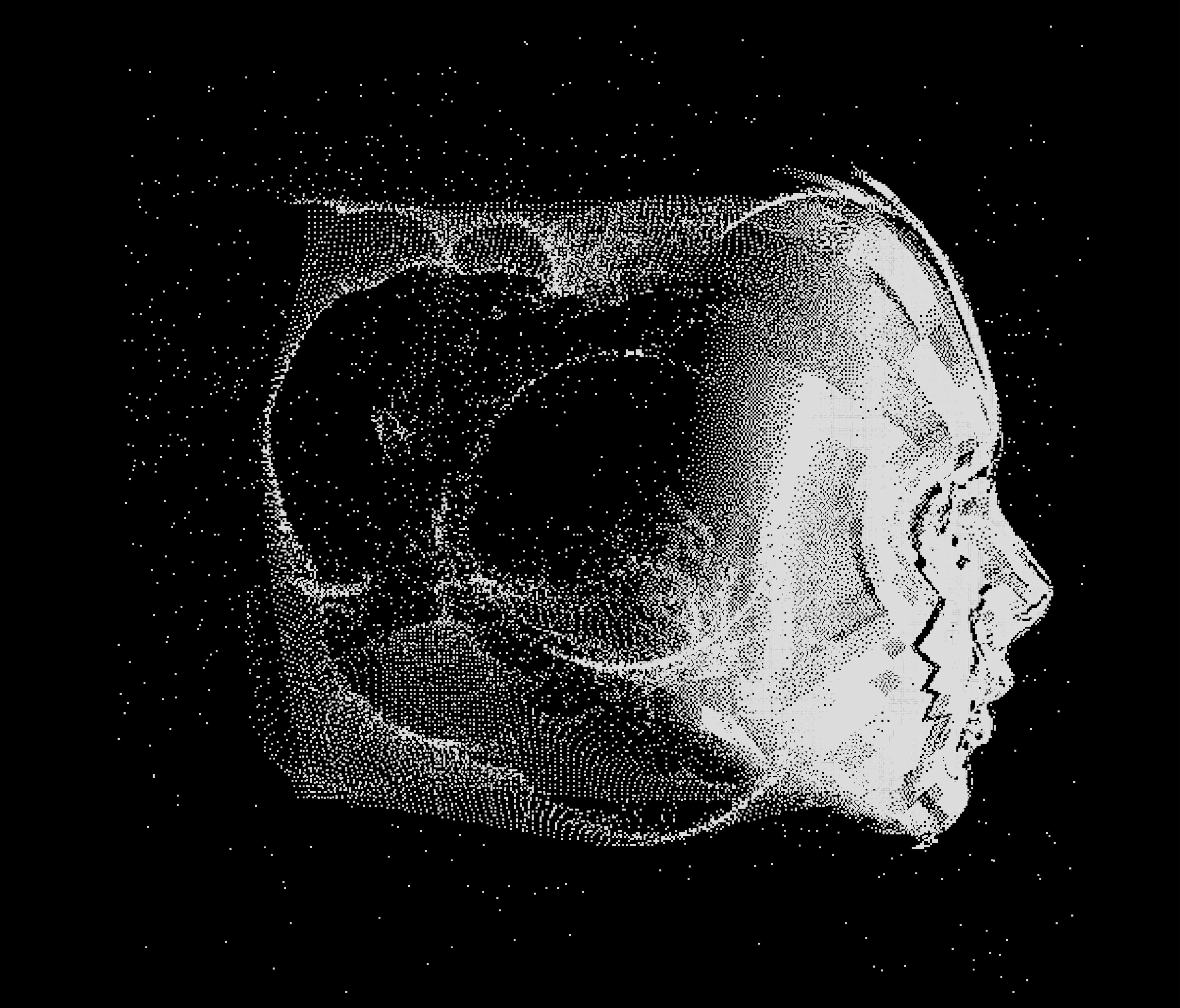
It’s hard to stop looking back and forth between these faces and the busts they came from.

Would you ever have sex with a robot?

Controversial physics theory says reality around us behaves like a computer neural network.

A new study used artificial intelligence to analyze relationship data from thousands of couples.

It’s a very human behavior—arguably one of the fundamentals that makes us us.

A small proof-of-concept study shows smartphones could help detect drunkenness based on the way you walk.

Researchers discover how to use light instead of electricity to advance artificial intelligence.

If machines develop consciousness, or if we manage to give it to them, the human-robot dynamic will forever be different.
▸
16 min
—
with

An algorithm may allow doctors to assess PTSD candidates for early intervention after traumatic ER visits.

Some of the world’s top minds weigh in on one of the most divisive questions in tech.
▸
17 min
—
with

An MIT system uses wireless signals to measure in-home appliance usage to better understand health tendencies.