artificial intelligence

Eric Siegel, Co-Founder & CEO, Gooder AI, argues machine learning (ML) projects go astray because their stakeholders focus too often on the technological fireworks — the “rocket science” of predictive models.
▸
9 min
—
with

With the right prompts, large language models can produce quality writing — and make us question the limits of human creativity.

“We should be informed and educated about the risks of AI, but we can’t be afraid,” Khan Academy founder Sal Khan told Big Think.

These scrolls are the only remaining intact library of ancient Rome — and they will crumble at a touch.

Can AI and animals coexist? Philosopher Peter Singer gives us a nuanced take on the issue.
▸
5 min
—
with

Wherever automation rises, religiosity falls.

Deepfakes featuring your digital double could replace emails and zoom presentations.

It could analyze a photo of the Martian surface in just five seconds. NASA scientists need 40 minutes.

What if you are the only person in the world who can think?

The Rijksmuseum employed an AI to repaint lost parts of Rembrandt’s “The Night Watch.” Here’s how they did it.

South Korea is piloting a CCTV system it hopes will save lives.
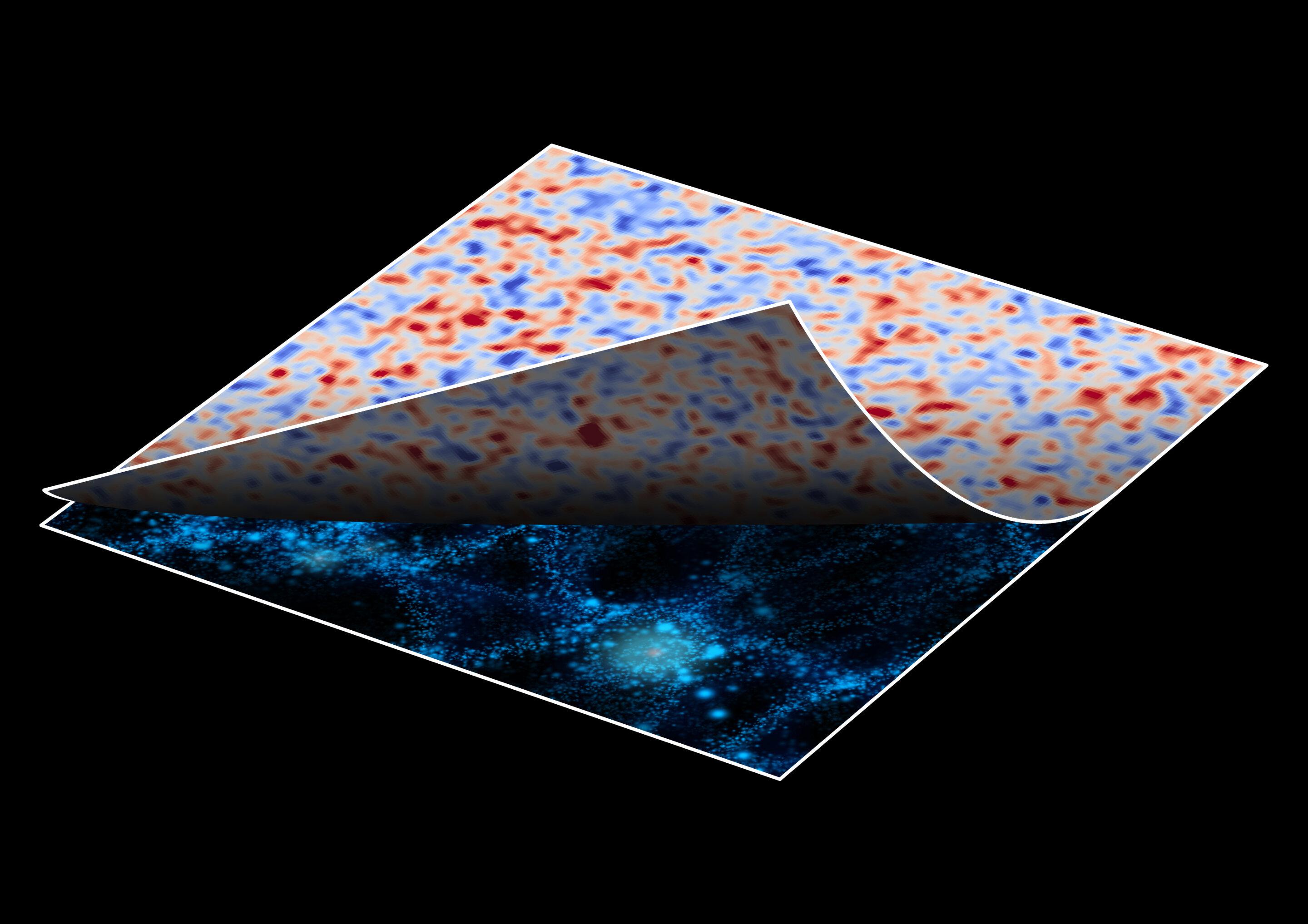
A new artificial intelligence method removes the effect of gravity on cosmic images, showing the real shapes of distant galaxies.

The pilot project is in 10 stores and is 85% accurate.

Climate change and artificial intelligence pose substantial — and possibly existential — problems for humanity to solve. Can we?

If computers can beat us at chess, maybe they could beat us at math, too.


If you ask your maps app to find “restaurants that aren’t McDonald’s,” you won’t like the result.

Companies can identify you from your music preferences, as well as influence and profit from your behavior.

Creating an afterlife—or a simulation of one—would take vast amounts of energy. Some scientists think the best way to capture that energy is by building megastructures around stars.
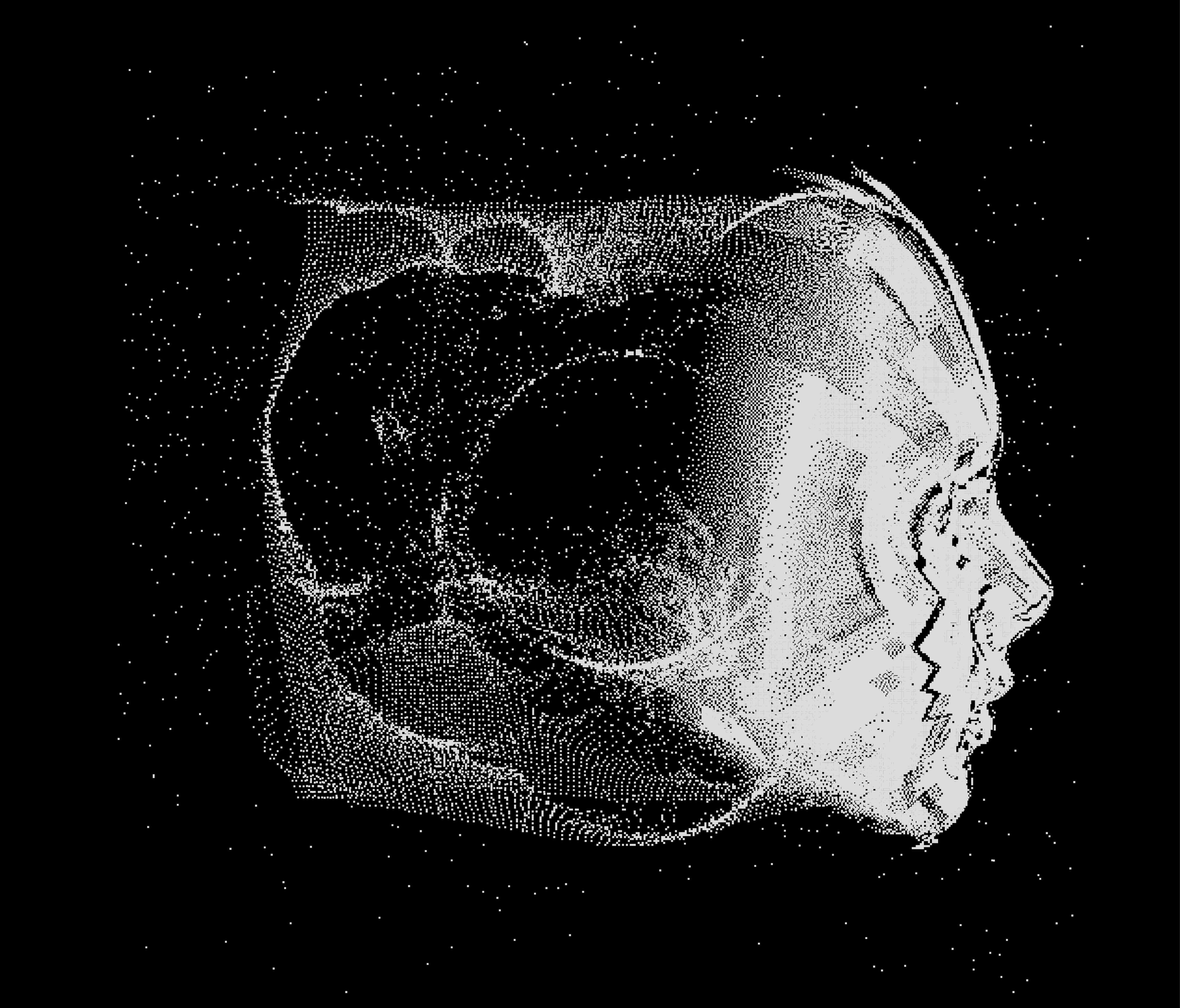
A physicist creates an AI algorithm that predicts natural events and may prove the simulation hypothesis.

“Deepfakes” and “cheap fakes” are becoming strikingly convincing — even ones generated on freely available apps.

Perspective twisting books on biology, social science, medical science, cosmology, and tech.

There’s a fortune to be made in data and silicon, and everyone is out for their share. Artificial intelligence is this century’s gold rush. Its promises scintillate in them there […]

A new MIT report proposes how humans should prepare for the age of automation and artificial intelligence.

Researchers make the case for “deep evidential regression.”

A heated debate is occurring at the University of Miami.

Can we stop a rogue AI by teaching it ethics? That might be easier said than done.
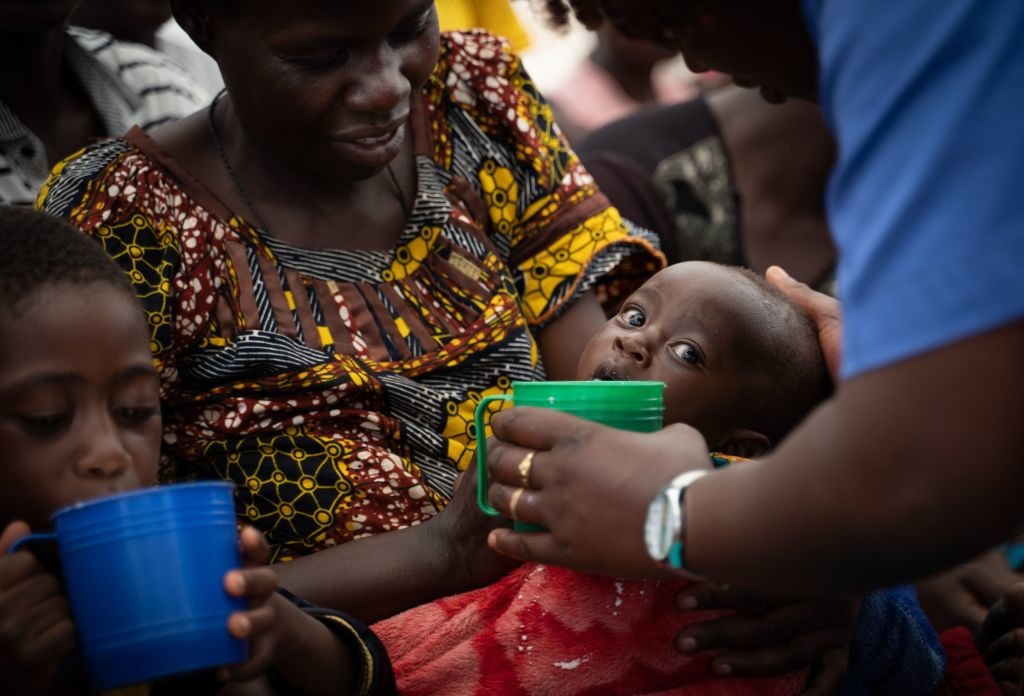
Can we end world hunger by 2030? Thanks to a new program, the data for it is all there.

It’s hard to stop looking back and forth between these faces and the busts they came from.

A new interactive documentary “How Normal Am I?” helps reveal the shortcomings of facial recognition technology.