algorithm

From 260-year-old ciphers to the most recent Zodiac Killer solution, these unbreakable codes just needed time.

There’s no telling whether machine-learned common sense is five years away, or 50.

Understanding “why” may be the key to unlocking an AI’s imagination.

In the future, you might voluntarily share your social media data with your psychiatrist to inform a more accurate diagnosis.

Max Planck Institute scientists crash into a computing wall there seems to be no way around.
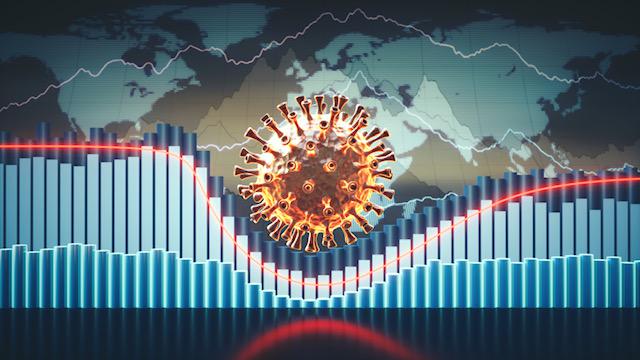
Northwell Health is using insights from website traffic to forecast COVID-19 hospitalizations two weeks in the future.

A new theory suggests that dreams’ illogical logic has an important purpose.

The more you like, follow and share, the faster you find yourself moving in that political direction.

This week, Big Think is partnering with Freethink to bring you amazing stories of the people and technologies that are shaping our future.
▸
6 min
—
with

A small proof-of-concept study shows smartphones could help detect drunkenness based on the way you walk.

Study finds quantum entanglement could, in principle, give a slight advantage in the game of blackjack.

An algorithm may allow doctors to assess PTSD candidates for early intervention after traumatic ER visits.

The Omni Calculator site is a stunning treasure trove of free calculators.

Some of the world’s top minds weigh in on one of the most divisive questions in tech.
▸
17 min
—
with

Mathematicians studied 100 billion tweets to help computer algorithms better understand our colloquial digital communication.

Researchers devise an effective new predictive tool for maritime first-responders.

Should humans fear artificial intelligence or welcome it into our lives?
▸
3 min
—
with

Researchers at UCSF have trained an algorithm to parse meaning from neural activity.
Our remarkable olfactory senses are modeled in a new research chip.

Through experiencing time in a nonlinear way, can artificial intelligence provide us more perspective?
▸
3 min
—
with

A new web startup is selling algorithmically produced nudes of non-existent women. There’s still some ethical concerns.

We encode our biases into everything we create: books, poems, and AI. What does that means for an increasingly automated future?
▸
4 min
—
with

An algorithm produced every possible melody. Now its creators want to destroy songwriter copyrights.
A computer coder and a lawyer decide they have a right to speak for all the songwriters that ever lived, those who are alive today, and all those yet to be born.
Scientists figured out how a certain treatment for skin cancer gives some patients a visual “superpower.”

We each have a way of moving to music that is so unique a computer can use it to identify us.

To solve the problem of negative digital disruption, technologies of the future must overcome the inequalities of today.
▸
8 min
—
with

Empathy is what allows us to understand works of art, right?

Almost all experts agree that coding will become nearly as ubiquitous as literacy in the future. But the nature of coding in the future may be very different.


The world’s always been changing, but it feels like it’s never changed so quickly as it does now. What life skills will that render obsolete?