Pan-STARRS solves the biggest problem facing every astronomer

Before you even look through your telescope, you need to know where to begin.
“If you can’t measure something, you can’t understand it. If you can’t understand it, you can’t control it. If you can’t control it, you can’t improve it.” –H. James Harrington
When you look out at any object in the Universe, the easiest thing to measure is how bright it is. But what you’re seeing might not accurately measure what the object is actually doing. Gas, dust and the atmosphere all contribute to blocking some of the light, preventing it from reaching your eyes. As atmospheric conditions change over time, what you see might change as well. Observations you make in the bluer part of the spectrum might be affected differently than observations in the redder part, as dust grains of different sizes have different sensitivities to a variety of wavelengths. If you’re looking at something hundreds, thousands or millions of light years away, you’ll need an entirely different calibration, all dependent on what’s between you and the object you’re trying to observe. It’s astronomy’s hardest problem: understanding how light is affected from when its emitted until it reaches your eye.

The Pan-STARRS1 observatory, after three years of observing all of the sky it’s capable of seeing from its perch in Hawaii, has just made public the results from the largest digital sky survey in history. Pan-STARRS sports the world’s largest camera, taking a 1.4 gigapixel image every 45 seconds. In a single night, it collects almost a terabyte of astronomical data; over three years of observations, that adds up to almost two petabytes: two quadrillion bytes of data. Every region of the sky accessible to it — spanning 75% of the entire Universe — has been imaged at least 60 times total: 12 times apiece in each of five different wavelength bands. The data is publicly available today, but what it means for science is unprecedented.
Every time a professional astronomer makes an observation, they have to calibrate their data. They need to know what they’re looking at in some standardized way. According to Ken Chambers, the director of Pan-STARRS observatory, every ground-based observatory will use these images and catalogs for their day-to-day observations. The previous large survey used for calibrations — the Digitized Sky Survey 2 — was good to about 13 milli-magnitudes, or an absolute brightness of about 1.2%. Thanks to Pan-STARRS, that’s been lowered to only 3 or 4 milli-magnitudes, or an absolute brightness of around 0.3%. Unlike previous surveys that surveyed the sky once or twice, Pan-STARRS surveyed it over and over again, enabling this unprecedented catalog.
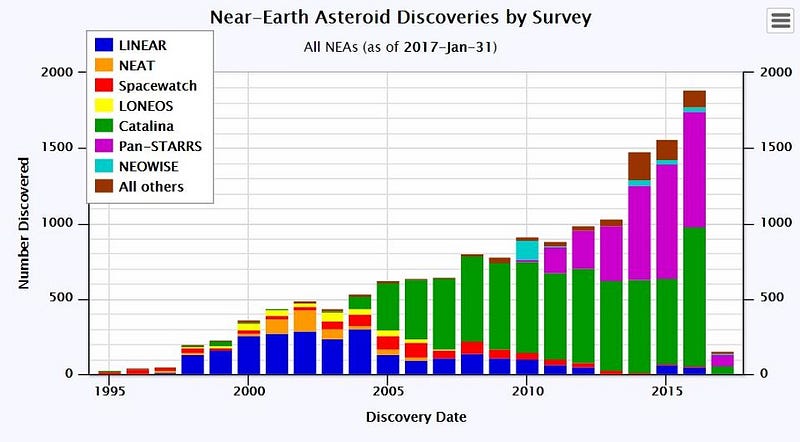
The science that came out of it alone is staggering. Nobody has had as much astronomical data in all of history as what Pan-STARRS has produced. They’ve discovered about 3,000 new near-Earth objects; tens of thousands of asteroids in the main belt, approximately 300 Kuiper belt objects (about a third of all the Kuiper belt objects ever discovered), and imaged a total of more than three billion verified objects. For those of you wondering, there’s no evidence for or against Planet Nine in the data, but the Pan-STARRS data does support that our Solar System ejected a fifth gas giant in its distant past.
Because the vast majority of these objects are stars within our own galaxy, and they’ve imaged them at different wavelengths so many time, they’ve been able to create the first 3D map of dust spanning the entire Milky Way. They’ve cataloged and categorized more stars than ever before, more deep-sky objects than ever before, and have given us a better understanding of what’s present in our galactic plane than we’ve ever known previously.

Stars can be classified by their color and magnitude to a better accuracy than ever before thanks to Pan-STARRS. From that, we can learn what type of star they are, where they are in their evolutionary sequence and what’s a dwarf, giant or other exotic type of star. We’ve also learned their distances and how much dust (and of what type) is present in the space between us and each star observed. All of the calibrated data is now freely available, and it empowers every astronomer to have a better starting point for every observation they make than was ever possible before. The European Space Agency’s GAIA mission — in space — will only be about half as good as Pan-STARRS at this.

Although the greatest leap forward will be for measurements within our own galaxy, the most distant observations go all the way out to galaxies and quasars at a redshift of z ~ 7, at a time when the Universe was only 6% of its current age. From new transients like asteroids and comets to ultra-distant supernovae, the Pan-STARRS database will be the new gold standard for identifying previously unseen objects in the Universe. Every observation, moving forward, has a new gold standard of calibrations to rely on. Every observatory will do their observatory work better, making Pan-STARRS the unsung hero of all astronomical observations to come. And because the data is publicly available, there’s a treasure trove of new discoveries just waiting to be found. It won’t be superseded until the 2030s, when the LSST has been operational for a decade. It isn’t even scheduled to come online until 2022.

If you were to print out the Pan-STARRS map of the Universe that it sees at full resolution, it would stretch for more than two kilometers in length. But it’s more than just a pretty picture. The data is something that every astronomer in the world should be using — and the Pan-STARRS collaboration is one they should be thanking (and citing) — every time they look at the sky.
This post first appeared at Forbes, and is brought to you ad-free by our Patreon supporters. Comment on our forum, & buy our first book: Beyond The Galaxy!