Study: Your Eyes Are Drawn to What’s Meaningful, Not to What “Sticks Out”
Imagine that moment right as you’re viewing a photo you’ve never seen before: How do your eyes go about choosing which parts of the image to look at first?
The leading theory in attention studies says that our eyes are drawn to things that are visually salient — or, those that “stick out” to us. However, a new study from UC Davis overturns that model by showing that “meaning” seems to be the primary guider of visual attention, while salience plays a secondary role.
“A lot of people will have to rethink things,” said John Henderson, professor at the UC Davis Center for Mind and Brain, who led the research. “The saliency hypothesis really is the dominant view.”
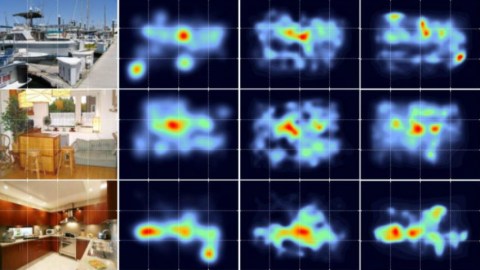
The findings, published in the journal Nature Human Behavior, come from a study that tracked the eye movements of people viewing images of real-world scenes — a kitchen, a boat dock, a messy room — for the first time.
To define which parts of the images were “meaningful,” researchers divided the images into circular overlapping tiles and submitted them individually to the online crowd-sourcing service Mechanical Turk, where users rated the tiles for meaning. For example, a tile showing only part of a window curtain would be rated low in meaning by users, while one showing a painting of purple grapes would be rated higher.

Rating the meaning of the tiles effectively turned the images into “meaning maps,” as researchers dubbed them. Salience was also mapped out, though by a much easier process — a computer program measured each part of the images for relative contrast and brightness.
The question now was: which of these maps would best predict the eye movements of the participants? To find out, researchers showed participants each image for 12 seconds and recorded the points at which they fixated their vision.

Real-world images alongside data representations of eye tracking (center left), meaning (center right) and salience (far right).
Results showed that “meaning was better able than visual salience to account for the guidance of attention through real-world scenes,” even though salience often overlapped with meaning.
So, why are our eyes drawn to meaning over what’s bright and shiny? The researchers suggest the reason might be that, when viewing real-world scenes, we use knowledge representations to help us prioritize where to look. For example, when we see a photo of a kitchen, we have a cognitive model that tells us what a kitchen is and where we might find meaning in that photo — among the objects by the sink, for instance, and not necessarily in the brightly colored curtains.
Henderson and postdoctoral researcher Taylor Hayes said they don’t yet have solid data on what exactly constitutes meaning in visual information. But they suggest their findings could have important implications for computer vision, such as training algorithms to scan security footage or identify and caption photos online.

On a broader level, the findings seem to echo a claim made by the phenomenological psychologist Ludwig Binswanger in his book “Being in the World”:
What we perceive are “first and foremost” not impressions of taste, tone, smell or touch, not even things or objects, but rather, meanings.
Binswanger essentially argues that we perceive the world with meaning detection before object recognition. This order of perception could be advantageous from an evolutionary perspective because determining the meaning of something is often more relevant than recognizing its exact nature. In other words, if you’re in the jungle and you spot a tiger rushing toward you, the first thought you want to have is danger, not necessarily that’s a female Bengal tiger.





