Language Pragmatics: Why We Can’t Talk to Computers

Speech recognition technology continues to fascinate language and cognitive science researchers, and Apple’s introduction of the Siri voice assistant program in its recent iPhone 4S was heralded by many as a great leap toward realizing the dream of a computer you can talk to. Fast-forward half a year later and, while Siri has proved to be practically useful and sometimes impressively accurate for dictation, the world has not been turned upside down. A quick Google search for “Siri fail” will provide you with the often unintentionally funny attempts by Apple’s voice recognition service to answer abstract questions or transcribe uncommon phrases.
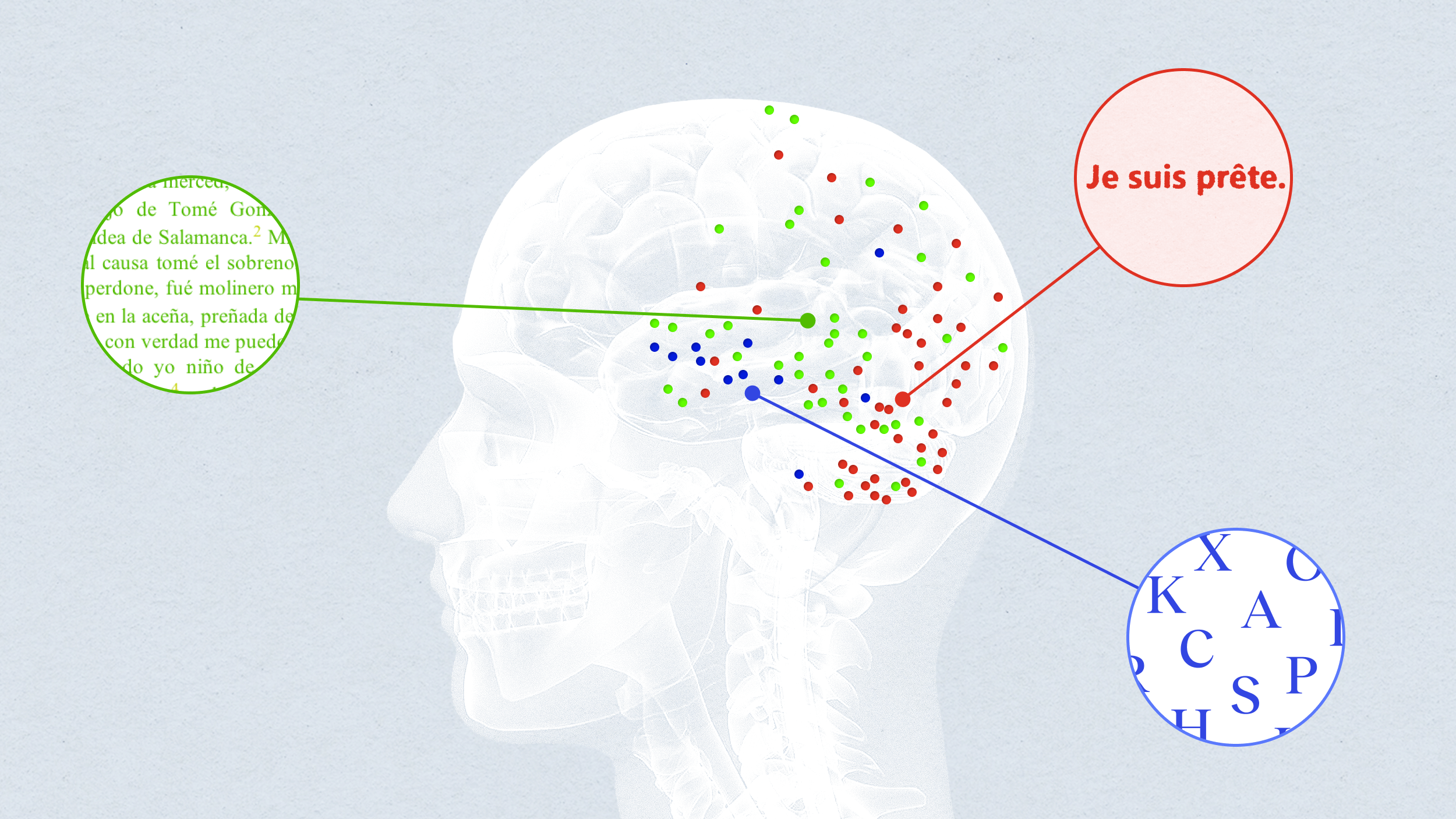
But in a day and age when computers can win at Jeopardy and chess programs can consistently defeat the best human players, why hasn’t voice technology reached a similar plateau of mastery? Here is cognitive scientist, popular author, and Floating University professor Steven Pinker exploring the issue in a clip from his lecture “Say What? Linguistics as a Window to Understanding the Brain.”
In short, it’s all about context, and the kinds of leaps easily achieved by humans in casual conversation have thus far remained outside the reach of dynamic language processing programs. One need only watch this infamous 2008 Microsoft demonstration of its Windows Vista voice recognition software to be reminded how nascent this technology remains for the most part.
But Siri works pretty well much of the time, right? Interestingly, Apple approached the voice recognition game using an framework that is about as far from how humans understand speech as you can get. Every time you speak to Siri, your iPhone connects to a cloud service, according to a Smart Planet article by Andrew Nusca, and the following takes place:
The server compares your speech against a statistical model to estimate, based on the sounds you spoke and the order in which you spoke them, what letters might constitute it. (At the same time, the local recognizer compares your speech to an abridged version of that statistical model.) For both, the highest-probability estimates get the go-ahead.
Based on these opinions, your speech — now understood as a series of vowels and consonants — is then run through a language model, which estimates the words that your speech is comprised of. Given a sufficient level of confidence, the computer then creates a candidate list of interpretations for what the sequence of words in your speech might mean.
In this sense, Siri doesn’t really “understand” anything said to it, it simply uses a constantly expanding probability model to attach combinations of letters to the sounds you’re saying. And once it has computed the most likely identity of your words, it cross checks them against the server database of successful answers to similar combinations of words and provides you with a probable answer. This is a system of speech recognition that sidesteps the pragmatics question discussed by Pinker by employing a huge vocabulary and a real-time cloud-based feedback database. And Siri’s trademark cheekiness? Apple has thousands of writers employed inputting phrases and responses manually into the Siri cloud, continually building out its “vocabulary” while relying on statistics for the context.
Does this constitute true speech recognition, or is this just a more robust version of old-time AOL chat bots? If this is the way that speech recognition technology will evolve in the future, do you think that it will cross a database threshold so as to be indistinguishable from true speech recognition, even if there’s no pragmatic “ghost in the machine,” as it were? Or will computers never be able to truly “learn” language?
Visit The Floating University to learn more about our approach to disrupting higher education, or check out Steven Pinker’s eSeminar “Say What? Linguistics as a Window to Understanding the Brain.”